Ensemble Learning Part 4: Stacking
In the evolving landscape of machine learning, there’s a method that stands out due to its robustness and versatility: stacking.
What is Stacking?
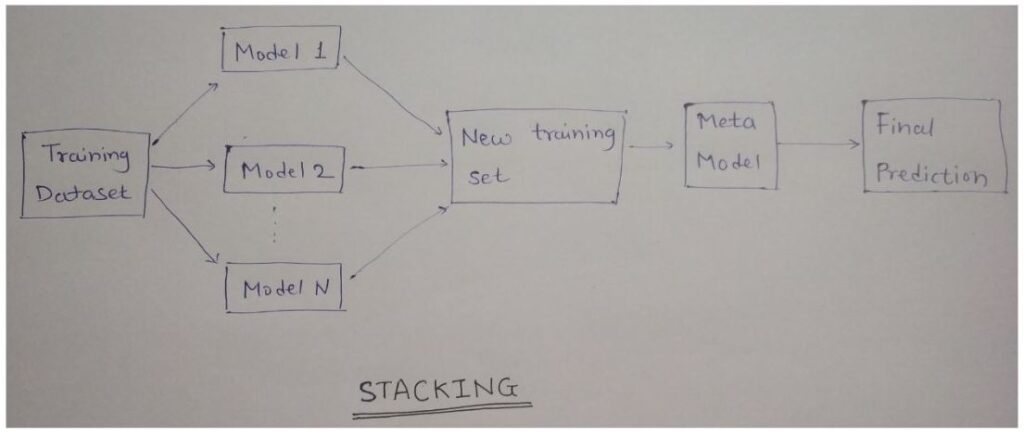
Stacking, or stacked generalization, is an ensemble learning technique that combines multiple machine learning models to produce a superior predictive model. Unlike other ensemble methods like bagging and boosting that work on a homogeneous set of models, stacking leverages a diverse array of models, often referred to as base models or level-0 models. The predictions from these base models are then used as input features for a meta-model, also known as the level-1 model, which makes the final prediction.
How Stacking Works
Step-by-Step Process
1. Divide Data into Folds:
– The training dataset is divided into several folds (typically K-fold cross-validation is used).
2. Train Base Models:
– Each base model is trained on a subset of the data (K-1 folds) and validated on the remaining fold. This process is repeated K times for each base model, ensuring that each fold serves as the validation set once.
3. Generate Meta-Features:
– The predictions from the base models during the K-fold cross-validation are collected to form a new dataset, often referred to as meta-features.
4. Train Meta-Model:
– The meta-features, along with the true labels from the validation sets, are used to train the meta-model.
5. Make Final Predictions:
– During the prediction phase, the base models make predictions on the test set. These predictions are used as input to the meta-model, which generates the final predictions.
Advantages of Stacking
1. Improved Performance: By leveraging the strengths of different models, stacking often achieves better predictive performance compared to individual models.
2. Flexibility: It allows for the combination of models with different characteristics and assumptions, enhancing robustness.
3. Model Diversity: Encourages the use of a diverse set of algorithms, reducing the risk of overfitting associated with relying on a single model type.
Conclusion
In conclusion, ensemble learning stands out as a powerful technique in the machine learning landscape, leveraging the collective strength of multiple models to achieve superior predictive performance. By combining the insights of various algorithms, ensemble methods can significantly reduce overfitting, improve accuracy, and increase robustness compared to individual models.
While ensemble learning does come with its own set of challenges, including increased computational cost and complexity, the benefits often outweigh these drawbacks. As machine learning continues to evolve, ensemble methods will undoubtedly remain a critical tool in the arsenal of data scientists and machine learning practitioners.
For those looking to implement ensemble learning, it’s essential to understand not only the individual algorithms but also how they can be effectively combined and tuned to work together. With thoughtful application and experimentation, ensemble learning can unlock new levels of performance and drive innovation in your machine learning projects.